Antlr–Another Tool for Language Recognition
可以根据用户编写的g4规则自动生成相关的java文件,提供api供用户调用,使得用户不需要关心规则文档的解析过程,直接通过相应的api即可完成数据的生成。
简介
功能
- 利用语法的描述(编写antlr的语法文件)可以自动化地生成指定编程语言的识别器,编译器以及相关解释器的框架 (能写出程序的程序)
- 可以通过断言来解决和识别到形式化表示中的冲突
- 可以支持相关的动作以及返回运行结果
- 在目标平台上自由使用
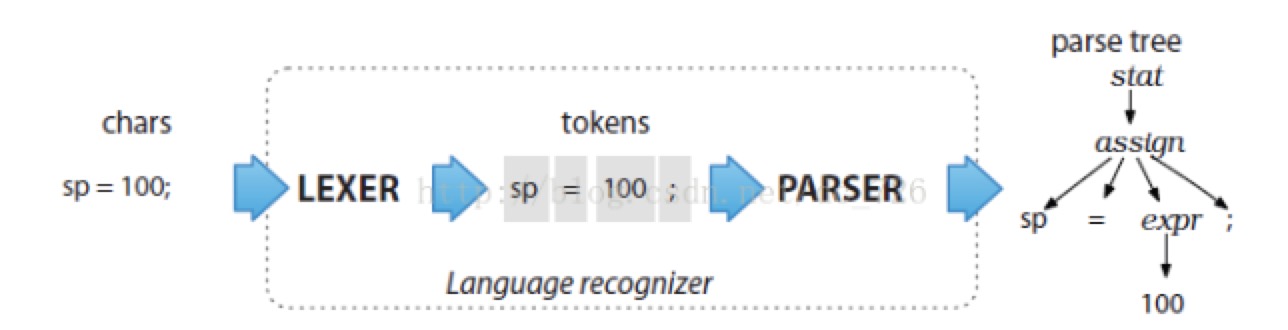
词法分析器 lexer
- 功能:翻译物理机器无法识别分辨的字符流,将它们转换为一系列的字符组(生成的tokens),涵盖了符号,关键字和标识操作等。
- 只做翻译工作,不理解各个字符的意思。
语法分析器 parser
- 功能:获取到lexer的结果,即所有的token,将其转换为目标语言语法中允许的格式。(是否满足语法规则中的rule)
- 对于抽象树的情况,如果匹配之后是合格的,就生成相应的语法抽象树,识别出各种语法成分。
- lexer 用于分析字符,parser用于分析token序列,都是分析器
抽象语法树
- 功能:在语法分析的同时做进一步处理
- 建立:在原来文法的基础上加入建树语法
- 树形结构易于遍历和处理。对于需要多次处理的翻译器来说,不需要多次调用解析器去解析,只需要高效地遍历语法树多次
树分析器
- 树分析器的处理对象是由结点构成的并且还是二维的抽象语法树,而语法分析器处理的则是由记号组成的记号流。
- 树分析器可以实现在遍历语法树时完成相关的语义处理,从而既完成了对源程序的语义分析又可以生成相应的源码。
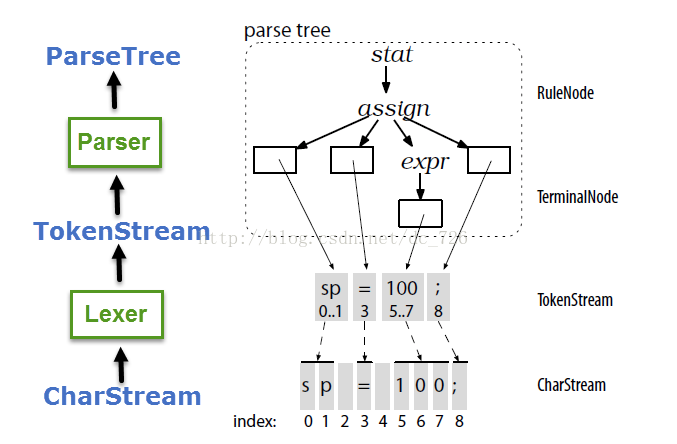
过程图示
解析树的应用图示
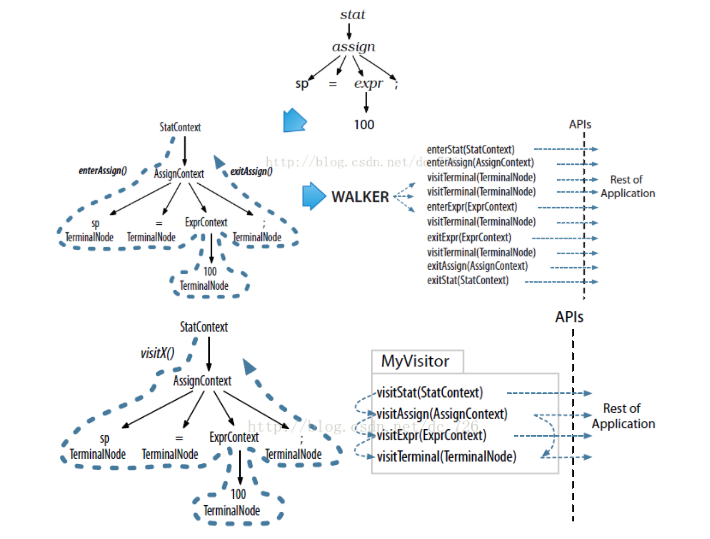
- antlr为每个rule生成一个context对象,它会记录识别时的所有信息。
- 两种遍历机制:Listener–全自动化的,深度优先遍历,我们只需要处理各种事件;Visitor–可控的,我们可以自行决定是否显示地调用子结点的visit方法。
遍历过程和api
语法规则:g4文件
- 文件结构:
| 语句 | 解释 |
|---|---|
| grammar Name | combined (lexer和parser) |
| options{…} | superclass,language,tokenVocab,TokenLabelType |
| import…; | parser or lexer file |
| tokens{…} | |
| @actionName{…} | @header,@member,@lexer::member,@parser::member |
| < |
rule defining 小写字母开头 |
- 常见语法规则
- 产生式左边:产生式右边—a:exp的形式表示规则,a是要定义的一个语句或者词,如果a是一个语句,则以小写字母开头,如果a是一个词,则以大写字母开头;exp是对a的具体定义。
- 字符串:单引号
- | 或
- ()+ 1或多
- ()* 0或多
- ()? 0或1
- {} 动作。当所跟的符号匹配后进行这个操作
- option{} 特殊的动作,内部可以设置参数
- program:statement+ 整体语法规则的起始点
- 终结符:var变量 int整数 string字符串 ws空白字符
- 非终结符:program程序体 statement语句 expression表达式 multExpr乘法因子表达式 atom因子
- 多个规则匹配,声明在词法文件最前面的规则生效