一. 变量和类型
有哪些数据类型
基本类型和引用类型的区别
| 基本类型 | 引用类型 |
|---|---|
| 值是不可变的 | 值是可变的 |
| 比较是值的比较 | 比较是引用的比较 |
| 变量存放在栈内存 | 值是保存在堆内存中的对象 |
null和undefined的区别
- null表示“没有对象”,即该处不应该有值
- 作为函数参数,表示该函数的参数不是对象
- 作为对象原型链的终点
- undefined表示“缺少值”,就是此处应该有一个值,但是还没有定义
- 变量被声明了,但是还没有赋值
- 调用函数时候,应该提供的参数没有提供,这个参数就是undefined
- 对象没有赋值的属性
- 函数没有返回值时候,默认返回undefined
==和===的区别
- ==:值的比较(隐式类型转换)
- ===: 不仅进行值的比较,还进行数据类型的比较
判断数据类型的方式
| typeof | instanceof | constructor | Object.prototype.toString.call | |
|---|---|---|---|---|
| 返回值 | 一个表示数据类型的字符串 | 是不是继承关系的boolean | 字符串 | [object xxx] |
| 优点 | 使用简单 | 能检测出引用类型 | 基本能检测出所有类型(除了null、undefined) | 检测出所有类型 |
| 缺点 | 只能检测基本类型(null是object) | 不能检测基本类型,不能跨iframe | 容易被修改,不能跨iframe | ie6下,undefined和null是object |
判断是不是数组的方式
- 两种不准确的:
instanceof和constructor - 两种准确的:
Array.isArray()和Object.prototype.toString()
会被判断为true的类型 & falsy类型
以下7种情况会被判断为false
- false关键字
- 0
- 0n(bigInt)
- 空字符串
- null
- undefined
- NaN
其他都会被判断会true
怎么把“2”变为2
- parseInt
- Number(“2”)
- / * -
二. 原型和原型链
原型和原型链
原型
构造函数、原型和实例三者之间:
- 创建一个函数的时候,会给这个函数创建一个prototype属性,这个属性指向函数的原型对象
- 所有原型对象会自动获得一个constructor属性,这是一个指向prototype属性所在函数的指针
- 当调用构造函数创建一个新实例后,该实例的内部将包含一个指针,指向构造函数的原型对象
原型链
当试图得到一个对象的某个属性时候,如果这个对象本身没有这个属性,那么会去它的 __proto__中去寻找,如果 obj.__proto__也没有,会在obj.__proto__.__proto__中去找,直到Object和Null
实现继承的方式
原型链
|
|
缺点:引用类型的值的原型的问题、不能向超类型的构造函数中传递参数
借用构造函数
|
|
缺点:方法都在构造函数中定义,无法函数复用,方法不能传
组合继承:原型链 + 构造函数 最常用
|
|
缺点:调用了两次超类型构造函数
原型式继承
基于已有的对象创建新对象
缺点:引用类型的值的属性的共享问题
寄生式继承
创建一个仅用于封装继承过程的函数,以某种方式增强对象
缺点:不能函数复用
寄生组合式继承 最理想
构造函数:继承属性
原型链的混成形式继承方法
优点:只调用一次SuperType构造函数,原型链保持不变
new操作符做了什么
- 创建一个新对象(object)
- 新对象隐式原型链接到构造函数显式原型(proto指向prototype)
- 执行构造函数并将构造函数作用域指向新对象(this指向新对象)
- 返回新对象
三. 作用域和闭包
作用域
- 全局作用域:在代码中任何地方都能访问到的对象
有三种情况:
- 最外层函数和最外层函数外面定义的变量
- 所有未定义直接赋值的变量
- 所有window对象的属性
- 函数作用域:函数内
- 块级作用域:let 和 const, 所声明的变量在指定块的作用域外无法被访问
函数声明提升和变量声明提升
- 同名情况下,函数的优先级大于变量的优先级
变量声明提升
12console.log(a); //undefinedvar a = 10;函数声明提升
1234console.log(f1); //function f1() { };function f1() { }; //函数声明console.log(f2); //undefinedvar f2 = function() { }; //函数表达式
this的指向
- this的值是在执行的时候才能确认,定义的时候不能确认
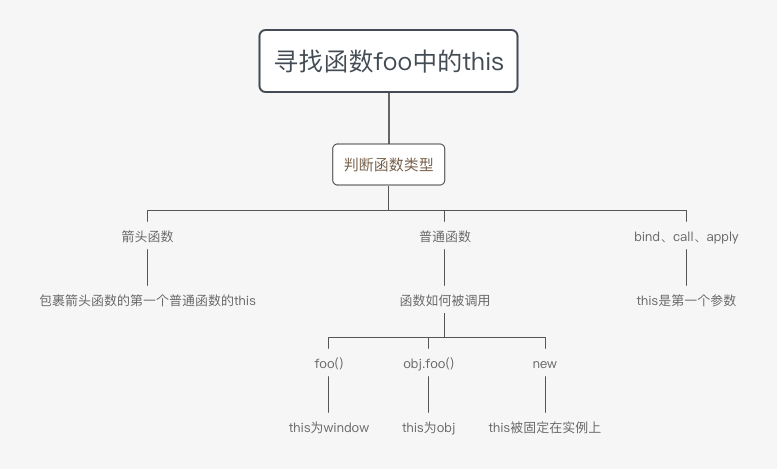
bind、call和apply的区别
- 这三个函数存在的意义是:改变函数执行的上下文(即运行时候this的指向)
- call和apply改变了函数的this之后便执行该函数,而bind则是改变了上下文之后返回一个函数,不会马上执行,需要调用
- call和apply的区别是参数
- 第一个参数都是改变上下文的对象
- call从第二个参数开始以参数列表的形式展现,而apply把除了改变上下文对象的参数放在一个数组里面作为它的第二个参数
闭包
- js在函数内部可以直接读取全局变量,但是在函数外部无法读取函数内的局部变量
- 闭包可以解决这个问题,闭包就是可以读取其他函数内部变量的函数,是定义在一个函数内部的函数
内部函数作为一个全局变量,会一直保存在内存中,而外部的函数使用了这个内部函数,所以也不会被销毁。所以每创建一个闭包,就会在内存中生成一个外部函数的成员变量的副本。
123456789function f1() {var n = 999;function f2() {alert(n)}return f2; //f2就是一个闭包}var result = f1();result(); //999闭包的应用场景
模仿块级作用域
12345678910function A(num) {for(var i=0;i<num;i++) { }console.log(i) //输出num}function A1(num) {(function(){for(var i=0;i<num;i++) { }})()console.log(i) //输出ReferenceError(i没有定义),匿名立即执行函数在这里就是闭包}存储变量,把一些不常变动且计算复杂的值存储起来,节省每次访问的时间
- 封装私有变量
- 常见错误,在循环中使用闭包
堆栈溢出和尾递归
- 堆栈溢出:每次执行js代码时,都会分配一定尺寸的栈空间,每次方法调用时候都会在栈里存储一定信息(参数、局部变量、返回值)等,当向数据库写了过多的数据,导致数据越界,覆盖别的数据,就是堆栈溢出。产生原因就是过多的函数调用,一般在递归中产生。
- 尾调用:某个函数的最后一步是调用另一个函数
function f(x) {return g(x); } - 尾递归:函数尾调用自身,由于只存在一个调用记录,所以不会发生栈溢出的错误;怎么做到尾递归?把所有用到的内部变量写成函数的参数。
内存泄漏
- 不再使用的内存区域没有被回收,导致这块内存被浪费
- 产生原因:全局变量、闭包、dom引用(比如table里的td引用)、被遗忘的计时器或者回调函数
- 防止:避免使用全局变量、及时清理、使用非匿名函数来引用局部变量…
模块化
- commonJS:主要用于服务端变成,加载模块是同步的,不适合在浏览器环境,因为浏览器资源是异步加载的。
- AMD:在浏览器环境中,可以并行加载多个模块,依赖前置(模块提前加载并且执行)
- CMD:与AMD相似,用于浏览器编程,依赖后置(模块懒加载再执行),模块的加载逻辑偏重
- ES6:可取代上面三者,成为浏览器和服务器通用的模块解决方案
四. 执行机制
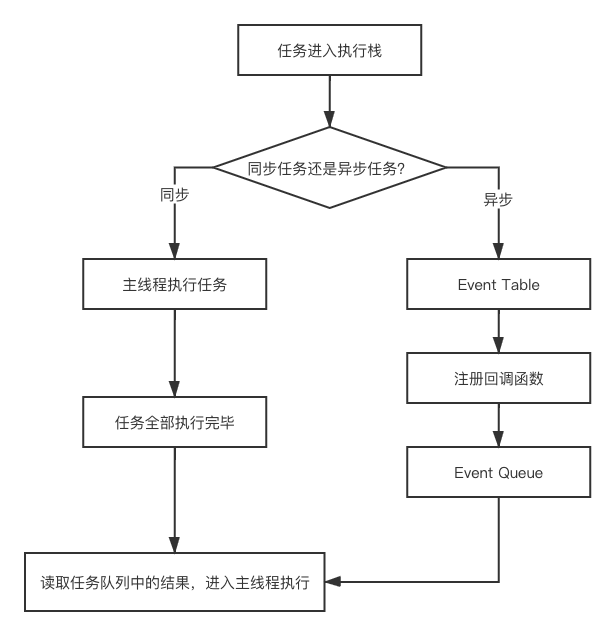
事件循环
avaScript引擎负责解析,执行JavaScript代码,但它并不能单独运行,通常都得有一个宿主环境,一般如浏览器或Node服务器,这些宿主环境创建主线程,提供一种机制,调用JavaScript引擎完成多个JavaScript代码块的调度,执行(是的,JavaScript代码都是按块执行的),并且循环不断,这种机制就称为事件循环。
- 同步运行
- 注册回调,不执行,通知线程触发的时候插入任务队列
- 继续执行同步代码
- 执行完后,检测是否有可用的回调,有就执行,没有就下一个事件循环
promise对象
- Promise构造函数接受一个函数作为参数,这个传入的函数有两个参数,分别是两个函数resolve和reject
new Promise(function(resolve,reject){ } ),resolve将promise的状态由未成功变为成功,并且将异步操作的结果作为参数传递过去,reject将状态由未失败转为失败,在异步操作失败时候调用,将异步操作报出的错误作为参数传递过去。 - 实例创建完成后,调用then方法,可以接受两个回调函数作为参数,第一个是状态变为resolved的调用,第二个是状态变为rejected的调用,两个函数都接受promise对象传出的值作为参数
- promise对象不受外界的影响,初始状态为pending,结果的状态为resolve和reject,状态只能由pending变为另外两种,并且改变后不可逆也不可再修改。
- then方法下一次的输入需要上一次的输出12345678let promise = new Promise((resolve, reject) => {reject("拒绝了")})promise.then((data) => {console.log('success' + data)}, (error) => {console.log(error);})
async/await
- async函数和生成器函数极为相似,只是将之前的*变成了async,yield变成了await,其实它就是一个能够自动执行的generator函数,不需要再通过
it.next()来控制生成器函数的暂停与启动。 - await帮我们做到了在同步阻塞代码的同时还能够监听promise对象的决议,一旦promise决议,原本暂停执行的async函数就会恢复执行,这个时候如果决议是resolve,那么返回的结果就是resolve的结果,如果决议是reject,必须用try…catch…来捕获这个错误
- await命令只能用在async函数中,如果用在普通函数,就会报错
宏任务和微任务
- 同步代码在执行完成后会检查是否有异步任务完成,并执行对应的回调。异步任务包括宏任务和微任务,微任务在宏任务之前执行。
| 宏任务 | 微任务 |
|---|---|
| setTimeout | process.nextTick (node) |
| setInterval | MutationObserver |
| setImmediate | Promise.then catch finally |
| requestAnimationFrame | — |
|
|